سلام به همه دوستان برنامه نویس 🙂
واقعیتش من چند وقتی بود که داشتم کتاب “هنر کدنویسی خوانا” یا همان The Art of Readable Code را میخوندم و دیدم خیلی کتاب مفیدی هست و بد نیست که برنامهنویسان عزیز این کتاب را بخوانند، برای همین تصمیم گرفتم کتاب را ترجمه کنم و چند فصل از کتاب را هم توی ویرگول منتشر میکنم. امیدوارم مفید باشه و برنامه نویسان عزیزی مثل شما بعد از خوندن این کتاب کدهای تمیزتری بنویسید و کمی به شما در مسیر پیشرفت توی حوزه برنامهنویسی کمک کند.
خب در این پست ویرگولی فصل هشتم کتاب هنر کدنویسی خوانا را با موضوع شکستن عبارتهای غول پیکر به قسمتهای کوچک، با هم دنبال میکنیم:
فصل هشتم: شکستن عبارتهای غول پیکر

ماهی مرکب غول پیکر، حیوانی شگفت انگیز و باهوش است، اما خلقت تقریبا کامل آن، یک نقص کشنده دارد چرا که مغز دونات شکل[1] این ماهی به دور مری[2] آن پیچیده شده است و اگر به یکباره غذای زیادی ببلعد، باعث آسیب رسیدن به مغزش میشود.
ممکن است بپرسید این چه ربطی به کد دارد؟ پاسخ این است که کد نوشته شده در تکههای بسیار بزرگ میتواند اثر مشابهای را داشته باشد. تحقیقات اخیر حاکی از آن است که اکثر ما در یک لحظه میتوانیم، تنها به سه یا چهار چیز فکر کنیم[3]. این به بیان سادهتر، یعنی هرچه عبارتهای کد بزرگتر باشد، درک آن سختتر خواهد بود.
کلید طلایی:
عبارتهای غول پیکر خود را به قطعات قابل هضمتر تقسیم کنید.
در این فصل روشهای مختلفی را برای دستکاری و تجزیه کد به شما خواهیم آموخت تا بلعیدن آنها سادهتر شود.
متغیرها را شرح دهید
سادهترین روش برای تجزیه یک عبارت، معرفی متغیرهای اضافهای است که یک زیرعبارت[4] کوچکتر را تولید میکند. این متغیر اضافی گاه «متغیر توضیح دهنده[5]» نامیده میشود، زیرا کمکی در جهت توضیح معنای زیرعبارت است. به عنوان مثال کد زیر را در نظر بگیرید:
if line.split(':')[0].strip() == "root":
...
و حال این کد مشابه را که همراه با متغیرهای توضیح دهنده است را مشاهده نمایید:
username = line.split(':')[0].strip()
if username == "root":
...
متغیرهای خلاصه
حتی اگر یک عبارت نیازمند توضیح نباشد(البته به این دلیل که میتوانید معنای آن را بفهمید)، باز هم گنجاندن آن عبارت در یک متغیر جدید مفید خواهد بود. البته اگر هدف از این کار صرفا جایگزینی آن کد با نامی کوچکتر است تا بتوان آن را راحتتر مدیریت یا به آن فکر کرد، این را یک متغیر خلاصه مینامیم.
به عنوان مثال عبارت زیر را در این کد در نظر بگیرید:
if (request.user.id == document.owner_id) {
// user can edit this document...
}
...
if (request.user.id != document.owner_id) {
// document is read-only...
عبارت request.user.id == document.owner_id شاید بزرگ به نظر نرسد، اما دارای پنج متغیر است که باعث میشود زمان مورد نیاز برای فکر کردن به آن بیشتری شود.
جمله «آیا کاربر مالک سند است؟»، مفهوم اصلی این کد است که با اضافه کردن یک متغیر خلاصه، این مفهوم میتواند به صورت روشنتری بیان شود:
final boolean user_owns_document = (request.user.id == document.owner_id);
if (user_owns_document) {
// user can edit this document...
}
...
if (!user_owns_document) {
// document is read-only...
}
ممکن است این تغییر، چیزِ زیادی به نظر نرسد، اما دستور if (user_owns_document) برای فکر کردن، کمی سادهتر است. همچنین تعریف user_owns_document در ابتدای کد به خواننده میگوید که «این مفهومی است که ما در طی این تابع به آن خواهیم پرداخت».
استفاده از قوانین دمورگان
اگر درس مدار یا منطق را گذرانده باشید احتمالا قوانین دمورگان را به خاطر دارید. این قوانین دو راه برای نوشتن یک عبارت Boolean به شکل معادل آن هستند:
1) not (a or b or c) ⇔ (not a) and (not b) and (not c) 2) not (a and b and c) ⇔ (not a) or (not b) or (not c)
گاه میتوانید با استفاده از این قوانین خوانایی بیشتری در یک متغیر Boolean ایجاد کنید. به عنوان نمونه اگر کد شما به صورت زیر باشد:
if (!(file_exists && !is_protected)) Error("Sorry, could not read file.");
می توانید آن را به شکل زیر بنویسید:
if (!file_exists || is_protected) Error("Sorry, could not read file.");
سوءاستفاده از منطق اتصال کوتاه
در اکثر زبانهای برنامهنویسی، عملگرهای Boolean ارزیابی اتصال کوتاه را انجام میدهند. به عنوان مثال، دستور if (a || b) در صورتی که مقدار a برابر true باشد، مقدار b را بررسی نمیکند. هر چند این رفتار بسیار مفید است اما گاهی میتواند برای تحقق منطق پیچیده به شکل صحیح مورد استفاده قرار نگیرد.
در اینجا مثالی از یک دستور تکی داریم:
assert((!(bucket = FindBucket(key))) || !bucket->IsOccupied());
در زبان انگلیسی، آنچه که این کد میگوید این است: «برای این key مقدار bucket را بگیر، اگر مقدار bucket برابر null نبود، پس مطمئن شوید که اشغال نشده است». هر چند این فقط یک خط کد است ولی واقعا سبب توقف اکثر برنامهنویسان میشود تا کمی در مورد آن فکر کنند. اکنون آن را با کد زیر مقایسه کنید:
bucket = FindBucket(key); if (bucket != NULL) assert(!bucket->IsOccupied());
این یکی حتی اگر دو خط کد باشد دقیقا همان کار را انجام داده و درک آن بسیار سادهتر است.
ممکن است سوال کنید پس چرا در نسخه اول، این کد به صورت یک عبارت غول پیکر نوشته شده است؟ ممکن است بگوییم شاید در آن زمان، برنامهنویس احساس باهوشی میکرده و برایش لذت خاصی در تقسیم کردن منطق به یک قطعه کد مختصر وجود داشته است. البته این قابل درک است و مانند حل کردن یک پازل نقاشی است که همه ما دوست داریم در محل کار تفریح هم داشته باشیم ولی مشکل این است که این نوع کد برای کسانی که میخواهند آن را بخوانند، یک دست انداز ذهنی در برابر سرعت خواندن کد ایجاد میکند.
کلید طلایی:
مراقب قطعه کدهای هوشمندانه باشید. آنها معمولا کسانی را که در آینده آن را میخوانند دچار سردرگمی میکنند.
حال ببینیم که آیا این بدان معنی است که شما باید از کاربرد رفتار اتصال کوتاه[5] خودداری کنید؟ خیر، موارد زیادی وجود دارد که میتوان از آن به شکل شفاف استفاده کرد، همچون:
if (object && object->method()) ...
شیوه جدیدتری نیز در اینجا وجود دارد که قابل ذکر است: در زبانهایی مثل Python، JavaScript و Ruby عملگر or یکی از آرگومانها را بر میگرداند(یعنی آن را به Boolean تبدیل نمیکند). بنابراین کد زیر:
x = a || b || c
می تواند برای انتخاب اولین مقدار صحیح از a، b یا c استفاده شود.
مثال: کشمکش با منطق پیچیده
فرض کنید که شما در حال پیاده سازی کلاس Range به این صورت هستید:
struct Range {
int begin;
int end;
// For example, [0,5) overlaps with [3,8)
bool OverlapsWith(Range other);
};
تصویر زیر چند نمونه از محدودهها را نشان میدهد:
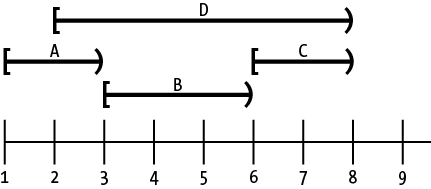
توجه کنید که end یک کلمه غیرفراگیر[1] است بنابراین A، B و C با یکدیگر همپوشانی[2] نداشته اما D با همه همپوشانی دارد.
یک تلاش برای پیاده سازی این وضعیت به این صورت است که قرار گیری هر نقطه انتهایی از یک محدوده در محدوده دیگر را بررسی میکند:
bool Range::OverlapsWith(Range other) {
// Check if 'begin' or 'end' falls inside 'other'.
return (begin >= other.begin && begin <= other.end) ||
(end >= other.begin && end <= other.end);
}
ولو اینکه این کد تنها دو خط طولانی باشد، باز هم موارد بسیار زیادی در آن بررسی میشود. در تصویر زیر همه منطق موجود در این کد نشان داده شده است.
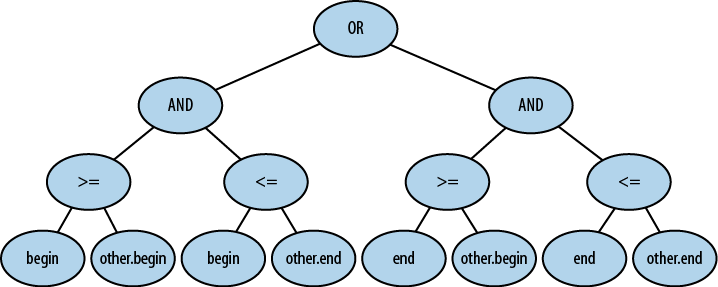
موارد و شرایط بسیاری وجود دارد که باید درباره آن فکر شود، چرا که رخ دادن سهوی یک اشکال در این مورد راحت است. صحبت از این است که یک باگ وجود دارد. زیرا کد قبلی ادعای همپوشانی محدوده [0,2) با [2,4) را دارد در حالی که در واقعیت این چنین نیست.
مشکل این است که باید در زمان مقایسه مقدارهای begin/end با استفاده از <= یا فقط > مراقب باشید. نمونه اصلاح شده آن را به این شکل است:
return (begin >= other.begin && begin < other.end) || (end > other.begin && end <= other.end);
اگرچه این مشکل برطرف شد ولی یک اشکال دیگر نیز وجود دارد! این کد مواردی که begin/end به صورت کامل دیگر موارد را پوشش میدهند، نادیده میگیرد. در اینجا نمونه اصلاح شده که این مورد را نیز مدیریت میکند، مشاهده میکنید:
return (begin >= other.begin && begin < other.end) || (end > other.begin && end <= other.end) || (begin <= other.begin && end >= other.end);
این کد بسیار پیچیده شده است. شما نمیتوانید انتظار داشته باشید کسی بعد از خواندن این کد با اطمینان بگوید که صحیح است. پس باید چه کاری انجام دهیم؟ چگونه میتوانیم این عبارت غول پیکر را تجزیه کنیم؟
پیدا کردن یک رویکرد ظریفتر
این نمونه یکی از مواقعی است که باید توقف کرده و رویکرد متفاوتی را در نظر بگیرید. آنچه به عنوان یک مشکل ساده شروع شد(یعنی بررسی اینکه دو محدوده با یکدیگر همپوشانی دارند یا نه) در نهایت به یک منطق پیچیده تعجب آور تبدیل گشت. این اغلب نشانهای است برای این مطلب که: باید راهی آسانتر وجود داشته باشد.
اما پیدا کردن یک راه حل ظریفتر نیازمند خلاقیت است. یک روش این است که ببینید آیا میتوانید مسئله را در جهت معکوس[2] حل کنید یا نه؟ بسته به موقعیتی که در آن قرار دارید، این کار میتواند با تکرار از طریق آرایهها، به صورت معکوس و یا پر کردن برخی از ساختارداده[3] از انتها[4] (به جای از ابتدا[5]) انجام شود.
در اینجا معکوس OverlapsWith() به معنی «همپوشانی ندارد» است. تشخیص این موضوع که دو محدوده با هم همپوشانی نداشته باشند، مسئلهای سادهتر است، زیرا تنها دو امکان وجود دارد:
- محدوده دیگر قبل از شروع این محدوده به پایان میرسد.
- محدوده دیگر پس از پایان این محدوده شروع میشود.
ما میتوانیم این مطلب را به سادگی در کد پیادهسازی کنیم:
bool Range::OverlapsWith(Range other) {
if (other.end <= begin) return false; // They end before we begin
if (other.begin >= end) return false; // They begin after we end
return true; // Only possibility left: they overlap
}
هر خط از کد بسیار ساده بوده و تنها شامل یک مقایسه تکی است. این باعث میشود تا خواننده توان ذهنی خود را صرف این مسئله کند که آیا <= صحیح است یا خیر؟
شکستن دستورات غول پیکر
هرچند این فصل درباره شکستن عبارتهای فردی[6] است، اما همین روشها، برای شکستن دستورات بزرگتر نیز کاربرد دارد. به عنوان مثال، موارد موجود در کد JavaScript زیر بیش از آن است که در یک نگاه بتوان همه آنها را درک کرد:
var update_highlight = function (message_num) {
if ($("#vote_value" + message_num).html() === "Up") {
$("#thumbs_up" + message_num).addClass("highlighted");
$("#thumbs_down" + message_num).removeClass("highlighted");
} else if ($("#vote_value" + message_num).html() === "Down") {
$("#thumbs_up" + message_num).removeClass("highlighted");
$("#thumbs_down" + message_num).addClass("highlighted");
} else {
$("#thumbs_up" + message_num).removeClass("highighted");
$("#thumbs_down" + message_num).removeClass("highlighted");
}
};
با اینکه عبارتهای فردی در این کد چندان بزرگ نیستند، ولی از کنار هم قرار گرفتن آنها، دستور غول پیکری شکل میگیرد که ممکن است سبب تعجب شما در یک لحظه شود. البته جای نگرانی نیست چرا که خوشبختانه به دلیل تشابه بسیاری از عبارتها میتوانیم آنها را به عنوان یک متغیر خلاصه، در بالای تابع قرار دهیم(همچنین این کار نمونهای از اصل DRY (یا خودت را تکرار نکن) است):
var update_highlight = function (message_num) {
var thumbs_up = $("#thumbs_up" + message_num);
var thumbs_down = $("#thumbs_down" + message_num);
var vote_value = $("#vote_value" + message_num).html();
var hi = "highlighted";
if (vote_value === "Up") {
thumbs_up.addClass(hi);
thumbs_down.removeClass(hi);
} else if (vote_value === "Down") {
thumbs_up.removeClass(hi);
thumbs_down.addClass(hi);
} else {
thumbs_up.removeClass(hi);
thumbs_down.removeClass(hi);
}
};
با اینکه لزومی به ساختن var hi = “highlighted” نیست، اما از آنجا که شش نسخه از آن وجود دارد، مزایای قانع کنندهای دارد، از جمله اینکه:
- کمک میکند تا از اشتباهات تایپی جلوگیری شود(آیا در مثال اول متوجه اشتباه تایپی رشته highlighted در مورد پنجم شدید؟)
- سبب کوتاهتر شدن عرض خط و در نتیجه سادهتر شدن بررسی کد در یک نگاه میشود.
- اگر نام کلاس نیاز به تغییر داشته باشد، فقط یک مکان برای تغییر آن وجود دارد.
یکی دیگر از روشهای خلاقانه برای ساده کردن یک عبارت
در زیر مثال دیگری در زبان C++ که در هر عبارت آن اتفاقات زیادی میافتد را مشاهده میکنید:
void AddStats(const Stats& add_from, Stats* add_to) {
add_to->set_total_memory(add_from.total_memory() + add_to->total_memory());
add_to->set_free_memory(add_from.free_memory() + add_to->free_memory());
add_to->set_swap_memory(add_from.swap_memory() + add_to->swap_memory());
add_to->set_status_string(add_from.status_string() + add_to->status_string());
add_to->set_num_processes(add_from.num_processes() + add_to->num_processes());
...
}
بار دیگر، چشمان شما با کدی دارای عباراتِ طولانی و مشابه هم (اما نه دقیقا یکسان) روبرو شده است. پس از ده ثانیه بررسی دقیق، ممکن است متوجه شوید که هر خط یک کار مشابه را در فیلدهای متفاوت انجام میدهد:
add_to->set_XXX(add_from.XXX() + add_to->XXX());
در C++ میتوانیم برای پیاده سازی چنین چیزی، از ماکروها استفاده کنیم:
void AddStats(const Stats& add_from, Stats* add_to) {
#define ADD_FIELD(field) add_to->set_##field(add_from.field() + add_to->field())
ADD_FIELD(total_memory);
ADD_FIELD(free_memory);
ADD_FIELD(swap_memory);
ADD_FIELD(status_string);
ADD_FIELD(num_processes);
...
#undef ADD_FIELD
}
اکنون که همه قسمتهای به هم پیچیده را از بین بردیم، میتوانید بلافاصله با یک نگاه ماهیت اینکه چه اتفاقی میافتد را درک کنید. کاملا واضح است که هر خط از کد کار مشابهای را انجام میدهد.
البته توجه داشته باشید که ما همیشه از کاربرد ماکروها دفاع نمیکنیم. در واقع اصل اولیه اجتناب از آنها است زیرا ماکروها میتوانند سبب ایجاد سردرگمی در کد شده و معرف باگهای ظریفی باشند. اما گاهی اوقات همچون این مورد، به دلیل ساده بودن میتوانند مزیت واضحی را برای خوانایی بهتر کد فراهم کنند.